Deep Learning (2/5): Improving Deep Neural Networks
This page uses Hypothes.is. You can annotate or highlight text directly on this page by expanding the bar on the right. If you find any errors, typos or you think some explanation is not clear enough, please feel free to add a comment. This helps me improving the quality of this site. Thank you!
Probability Distributions Bias/variance Over-/underfitting Regularization L2-Regularization Dropout Early Stopping Data Augmentation Input Normalization Weight Decay Exploding/vanishing Gradient Mini-Batch Gradient Descent Exponentially Weighted Average Momentum RMSprop Adam Learning Rate Decay Local Optima Softmax Pandas & Caviar Hyperparameter Tuning Batch Norm TensorFlow
T his course focuses on common problems you might encounter when working on DL-projects. The course includes some useful recipes that might help you where to tune your algorithm when it does not perform the way it should. It also introduces some best practices for training your own NN and also some useful techniques to speed up the learning process.
Table of Contents
- Course overview
- Hyperparameter tuning
- Training-, Validation- and Test-Set
- Regularization
- Input normalization
- Initialization
- Model Optimization
- Hyperparameter tuning
- Batch Normalization
- Multiclass classification
Course overview
Week 1 introduces the various hyperparameters of a model and how to choose reasonable values for them. You will also learn how to identify problematic behavior of algorithm and where it may be rooted. Week 2 introduces some optimization algorithms that may speed up the overall learning process. Week 3 wraps up on hyperparameters and how to find optimal values for them. It also introduces Softmax as an alternative activation function for multiclass-classification. This is also the week where you get to know a DL-Framework (TensorFlow) for the first time.
Hyperparameter tuning
We have learned in part 1 that setting up a NN is a highly iterative and empirical process. There is no algorithm that can calculate the optimal values for the hyperparameters (e.g. number of layers, hidden units or learning rate) for you. Sometimes there are a few rule of thumbs you can use. But more often the values for the hyperparameters are chosen more or less intuitively.
It is also true that results from one domain can seldom be transferred to another. So if you have a NN that works well in computer vision, it is not guaranteed that this NN also works well for audio or language processing tasks. Most of the time it is impossible to “guess” the optimal values in the first try. They have to be manually adjusted to improve learning. This requires experience which can be obtained through practice - or by someone who tells you what works (and what not). And this is exactly what this course is aimed at.
Training-, Validation- and Test-Set
The available labelled data is usually split into three parts:
| Name | Purpose | Ratio |
|---|---|---|
| training set | for the actual training of the model | >90% |
| validation set (sometimes also called dev-set) | for parameter optimization | <5% |
| test set | for modelevaluation | <5% |
In earlier years of ML a usual split was 60/20/20% (training/test/validation). You can sometimes still see these numbers in textbooks. This split was valid for times when labelled data was scarce and you had to make sure to have enough instances in your validation or test set. However, for a lot of DL tasks nowadays there is enough data available, so we can use a lot bigger portion for training while optimizing/testing with a comparatively small validation/test set. The suggested ratios in the table above apply to scenarios where a lot of training data is available. This is kind of a precondition for DL models in order to achieve a good performance. However, we live in an imperfect world and labelled data might still not always be readily available. In such situations your split ratios may vary in favor of a larger validation and/or training set. It really depends on your specific setting.
The reason we split into different set is that we can optimize the model by using data it has never seen before. We do this to reduce overfitting. We can later evaluate the model with another set of instances it has - again - never seen before and therefore get a realistic sense for how the model will perform in the real world for unseen data.
If not much labelled data is available, people sometimes use only a training and a test set and then optimize their model by using the test set. In fact, this is sometimes done regardless of the amount of labelled data. But be aware: this is actually wrong! If you optimize your model on your test set, your model has (implicitly) already seen this data (indirectly, through optimization) and you’re left with no more unseen data to evaluate your model on. When evaluating your model with the same test data you used for optimizing the parameters the results might be too optimistic!
Bias and variance
A well known problem in ML is overfitting. Overfitting means you trained your model applies very wellon the training data but does not generalize well for unseen data. In contrast, you can also train your model too little. We then speak of underfitting. The following image shows typical graphs for the error on the training set and the error on the test set with a model that is overfitting. Notice how the error on the training and test data decrease up to some point when the error on the test data starts to increase again. That’s the point when your model starts to overfit!
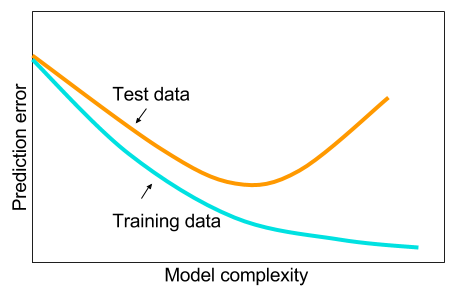
In context of over- or underfitting there are two other terms often used: bias and variance. We speak of high bias when your model is underfitting, i.e. it is not trained enough and biased too much towards the training data. In contrast, we speak of high variance if your model is trying too hard and is therefore overfitting. The following picture visualizes how a model with high bias or high variance might classify the instances:
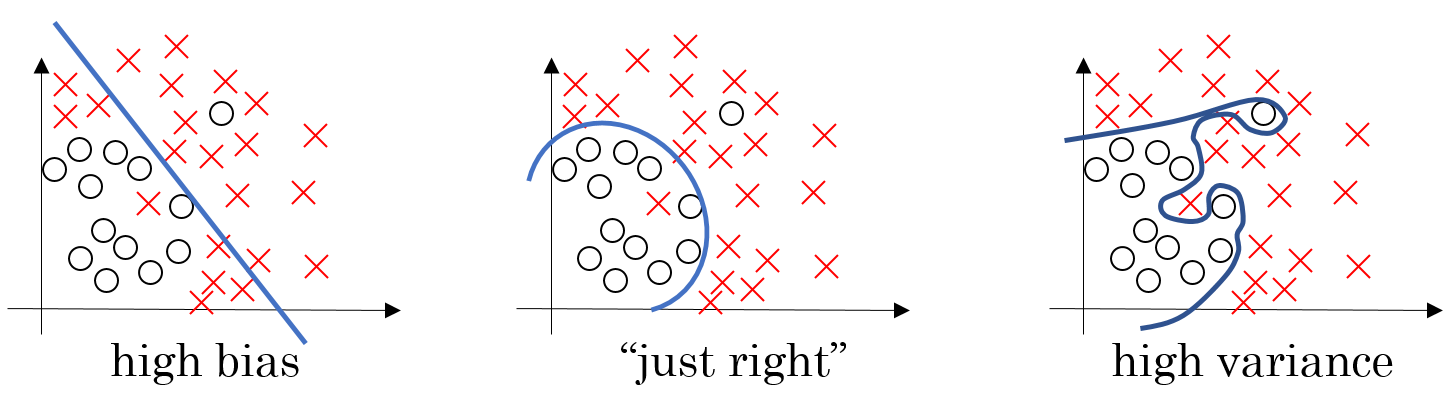
The following table shows the different combinations of high/low bias and variance and what they mean (train set error means your cost on the training set and dev-set error means the error when optimizing on the dev set):
| dev-set error high | DevSet error low | |
| train set error high | high bias and variance | you got lucky (unrealistic case) |
| train set error low | high bias | your model performs well |
If your model suffers of high bias, you could train a bigger network, train longer (i.e. more iterations) or choose a different architecture. If your model suffers of high variance you should try to get more training data or apply some of the regularization techniques presented below.
To assess the quality of a model the difference between bias and variance is relevant. Generally, we try to keep this difference as small as possible.
Regularization
We can prevent overfitting by applying one or more regularization techniques which are presented in this chapter.
Regularizing the cost
A common approach for regularization is to add a regularization term to the cost function. For example, we can add regularize the cost function for Logistic Regression when optimizing the parameters and :
The last term is called the regularization term and uses the regularization hyperparameter , which determines the degree of the regularization. In this case, we use in the regularization term, which is called the L2-norm and is defined as follows:
However, we could also use the L1-norm which is less common but would be defined as follows:
Regularization term for NN
We have seen now how we can regularize the cost in Logistic Regression by using a regularization term (see ). We can regularize the cost in a NN with several hidden layers (and therefore several weight matrices ) the same way using a similar regularization term:
Note that the term is basically just the L2-norm, but is often called the Frobenius norm for historical reasons. It calculates the values by iterating over the rows and columns of a weight matrix for Layer with dimension and is defined as follows::
So adding a regularization term to the cost function leads to higher costs. Therefore high values in are penalized when calculating the cost. Note that the bias parameter is usually not regularized. This is because is usually a high dimensional matrix with lots of values and just a scalar, so regularizing won’t make much of a difference.
Adjusting parameter update
Because we changed the calculation of the cost by using a regularization term, we also need to adjust the derivative when updating the weights:
Re-writing the above equation a bit gives us the following equation:
We see in the last form that the weight matrix is multiplied with , which is a value smaller than one. Cosequently, the values of the weight matrix become a bit smaller in each iteration. That’s why L2-Regularization in NN is sometimes also referred to as weight decay.
Why adding the regularization term reduces overfitting
The reason why a regularization term leads to a better model is that with weight decay single weights in a weight matrix can become very small. The weight matrix is then in fact a sparse matrix. This leads to single nodes virtually being cancelled out in the NN and effectively to a simpler NN.
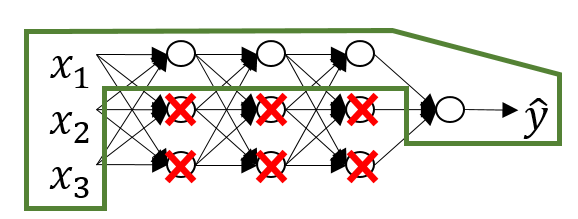
Another reason is that the activation function is roughly linear for values close to zero. We can observe this when using as our activation function:
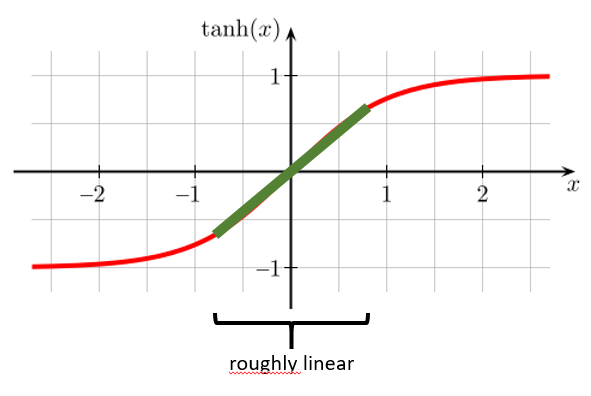
Because the values in become close to zero, the cell value (before activation) is also close to zero. Therefore, the values after activation mostly lie in the linear region of the activation function. Therefore the NN calculates something more or less close to a linear function. As we have seen in part one, linear classifiers can only calculate linear boundaries. Therefore the higher the value for the more we force the NN to become close to a linear function and prevent it to calculate over-complicated boundaries. This consequently reduces overfitting.
Dropout
Another technique to reduce overfitting is using Dropouts. With dropouts we mean completely cancelling out individual neurons during test time by multiplying their weights by zero. By doing this we prevent single neurons in the NN to become too important for learning. In other words: We force the NN to learn from other features too. To make this work, we must cancel out different units in each iteration during training time. When doing this, the ratio of cancelled out neurons in each layer should not be more than 50%. Dropout regularization works surprisingly well for certain domains such as computer vision. On the downside we can’t really rely on the costs calculated by anymore because different units are cancelled out in each iteration. To get around this you should plot your costs without and then with dropout regularization to make sure they are really decreasing. Important: during test time we mustn’t use dropout regularization anymore because we want to see the performance of the full network!
Other regularization techniques
Minimizing the costs and preventing overfitting should be treated as separate tasks. This principle is also referred to as orthogonalization. There are several other techniques you can try to reduce overfitting.
Data augmentation
The most common approach to reduce overfitting is to use more training data. But sometimes it is impossible or very expensive to get additional labelled data. We then can try to generate new synthetic data from the old. If we e.g. train an image classifier, we can easily generate new images from the old by applying one or more of the following operations:
- mirroring
- rotation
- random cropping
- shifting
- tilting
- local warping / adding some noise
- color shifting
There are tools and libraries to help with data augmentation (e.g. Agumentor for image data). However, this can only be done to some extent because the underlying image information is factually still the same and using more of “the same” will not improve the model significantly anymore at some point.
Early stopping
Another very simple method to prevent overfitting is to abort training as soon as we observe the test error increasing again. However, this is problematic because we prevent the model from exploring the whole label space. It also violates the principle of orthogonalization.
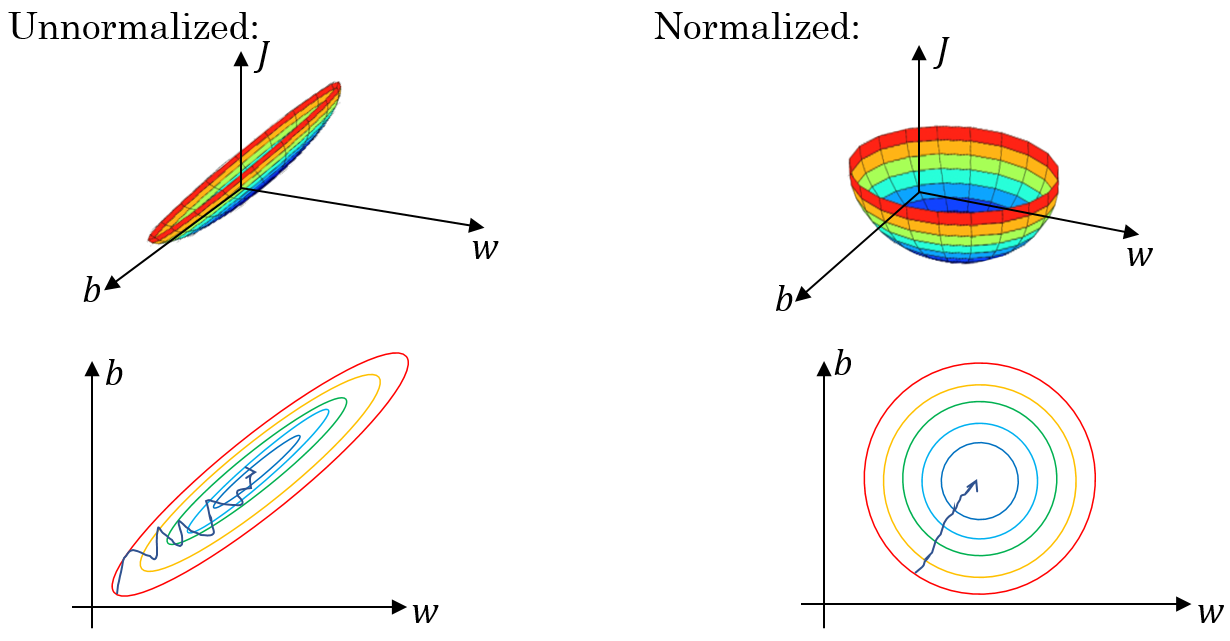
Input normalization
A very useful technique to speed up the learning process is to normalize the NN’s input. We can do this in two steps:
- subtract the mean:
- divide by the variance:
Subtracting the mean will center the values around their average value, meaning that samples with feature values close to the mean vector will have values close to zero. Dividing by the variance will put the feature values on a similar scale, meaning that big differences between values in skewed data will be reduced. Normalizing the inputs leads to the cost function converging more quickly. However, when performing input normalization this way you should make sure to use the same values for and to normalize the training and the test set!
Initialization
The problem with very deep NN is that for each layer we have a weight matrix with values that can be big (greater than 1) or small (less than 1). Because each layer multiplies the previous layer’s activation with its own weight matrix, this can lead to very high or very small values for . This applies if all (or a lot) of the weight matrices contain big values and consequently the value for exponentially increases/decreases. A similar argument can be used to show that also the gradients will exonentially increase/decrease (exploding or vanishing gradients).
A partial solution for this problem is a careful initialization of the parameters for the NN. To better understand this let’s observe the following example of a single neuron:
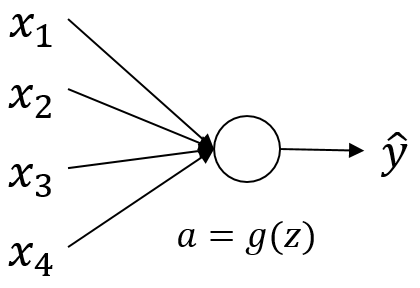
Calculating the cell state is done as follows:
To prevent from becoming very large we have to make sure the single summands don’t become too large. We can do this by multiplying the weight matrix with its variance:
This variant is called He initialization is often used in conjunction with a ReLU activation function. There are other variants for other activation functions, such as Xavier initialization for activation function:
The following picture illustrate the different results for different initializations. Note that for zero-initialization the classifier predicted (does not belong to class) for all instances!
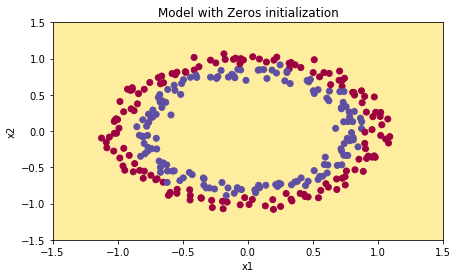 |
 |
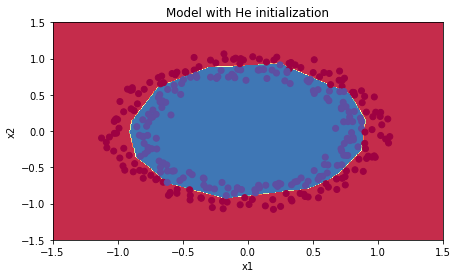 |
Model Optimization
It is often hard to find the best model because model training is time-intensive and it can therefore take some time before you get some feedback. To speed up the training process there are a few algorithms.
Mini Batch Gradient Descent
We have learned in part one how vectorization can reduce computation time because all the samples are processed in one go. However, this does not work well for very large datasets anymore because the sample matrix would simply become too large. We can therefore partition the training set in mini batches, which are processed one by one. Usually, the training data is shuffled prior to partitioning to get randomized batches.
We can identify an individual batch from a set of batches by adding the superscript . The processing per batch is than as before for the whole training set:
- forward-propagation:
- calculate costs:
- backprop to compute gradients w.r.t.
- parameter update:
You can see that in fact we are doing exactly the same thing as before, but with a single batch instead of the whole training set. A single iteration over all batches of the training set is called epoch. Like before, training one the whole training set is done with more than 1 iteration. You can thereefore think of MBGD as nesting the existing loop for the training in an additional loop over the batches.
Understanding MBGD
Despite having an additional loop, training with MBGD is usually much faster than processing all the training data at once. Because the batches contain different samples, it is very likely that the costs will not always monotonically decrease from one batch to the next. They usually oscillate a bit, but generally the costs go down:
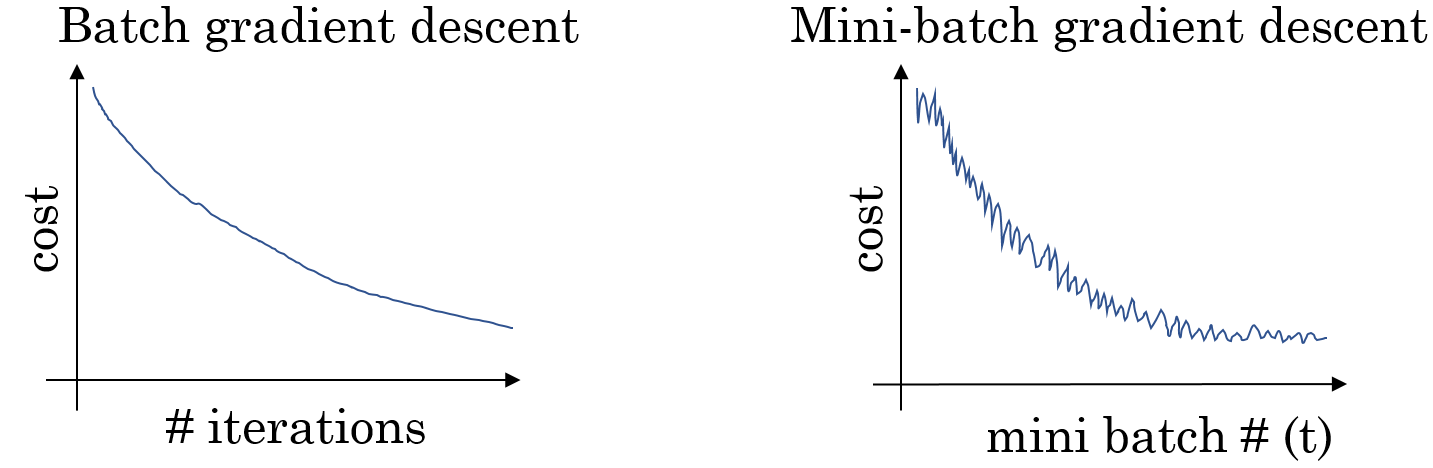
There are two extrema for choosing the size of a single mini-batch:
- : This corresponds to normal Gradient Descent whereas each training sample is processed individually. This is not recommended because one epoch would take too long.
- : This is called stochastic Gradient Descent, which is sometimes done, but we lose the performance advantage of a vectorized implementation

Generally you should choose a value between 1 and for . Powers of 2 (64, 128, 256, …) are often chosen because they offer some computational advantages. But more important is that a single mini-batch fits into your computer’s memory.
Exponentially weighted average
There are more sophisticated optimization algorithms than GD. They often make use of something called exponentially weighted (moving) average. An EWA can be calculated by recursively by using the previous average , a parameter and the current parameter value :
For example consider the following plot of temperatures over different days (blue dots).
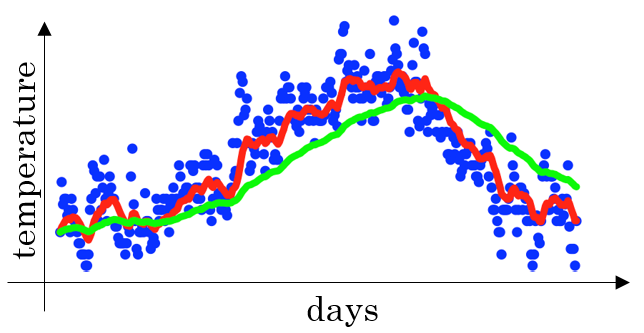
The parameter can here be somehow seen as the window size that is used to calculate the approximate average. A value of would correspond to days (red line). A larger value of would lead to a larger window of 50 days and consequently to a smoother line, which adapts more slowly to temperature changes and is therefore shifted to the right (green line). In contrast, a smaller value for would consider fewer days and be more wiggly.
When implementing the EWA and initializing you can observe that the graph of the EWA is too small because the value for the first average is too low. To come around this, one can simply divide the calculated average by . This is called bias correction. So formula can be adjusted as follows:
Momentum
Gradient Descent with momentum (GDM) is a variant of GD which converges faster by using moving averages. GDM can be best understood by observing the convergence of the cost function over a contour plot:
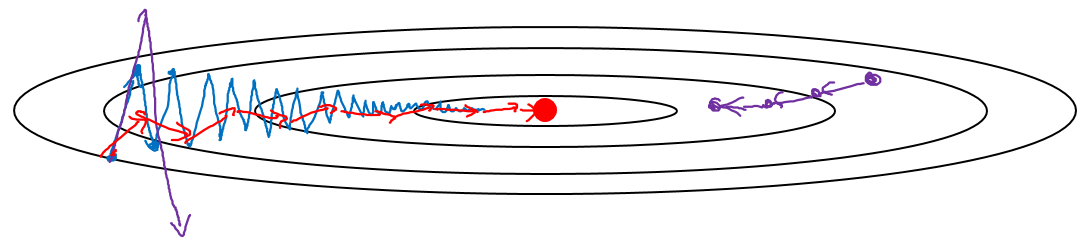
In this figure convergence without GM would follow the blue line, which oscillates quite a bit. This oscillation prevents us from choosing a larger learning rate, because then we would overshoot and maybe even diverge from the optimal costs (purple line). What we want is the oscillation in vertical direction (e.g. the direction for parameter ) to damp out because it slows down the learning progress. On the other hand we want learning to go fast in the horizontal direction (e.g. the direction for parameter ). By computing the moving averages over the derivatives and GDM smoothes out the steps of GD by cancelling out positive and negative values of the GD (which are responsible for the oscillation in the first place). This makes the GD being more directed towards the optimum and using fewer steps.
So what GDM tries to do is use the learning rate’s momentum for faster convergence in horizontal direction. You can think of the plot above as the contours of a bowl where we roll a ball to its bottom. The averages is responsible for its velocity, and the derivatives for its acceleration. GDM tries to do this by using a parameter . To better understand this, remember how we updated the parameters in GD:
GDM calculates the EWA of the derivatives first and then uses the result to update the parameters:
Note that bias correction is not usually done in practice because after a few iterations the moving average will have moved up enough to produce good values.
RMSprop
Another algorithm to increase learning speed that makes use of momentum is Root Mean Square prop (RMSprop). The calculation is similiar to GDM (see ), however the derivatives are squared (element-wise) and the update is a bit different.
Note that the parameter is used to prevent division by zero.
In contrast to GDM, RMSprop tries to damp out the vertical oscillation. In other words, for equation we want to be small, because then we would divide by a small number, which results in a bigger update. On the other hand we expect to be large, because then we divide by a large number which would make the update small.
Adam
It turned out over time that a lot of optimization algorithms do not generalize well. Often a certain algorithm only performs well for one specific type of problem. Adaptive Moment Estimation (ADAM) is one of the few algorithms that can be applied to a wide range of learning problems. ADAM is a combination of both GDM and RMSprop. In order to not confuse the differet parameters we will use for the parameter of GDM and for the parameter of RMSprop. The algorithm can then calculate Gradient Descent for a given mini-batch as follows:
- Initialization:
- For each mini-batch in iteration do:
- calculate the derivatives
- calculate moving average with GDM: use to determine the window size
- calculate RMSprop: use to determine damping
- apply bias correction:
- update parameters:
To sum up, ADAM uses the following hyperparameters:
| hyperparameter | meaning | comment |
|---|---|---|
| learning rate | needs to be manually tuned (but ADAM allows for bigger values than GD!) | |
| window size to calculate moving average of (first moment) | 0.9 is a reasonable value | |
| damping rate to calculate moving average of (second moment) | 0.999 is a reasonable value | |
| term to prevent division by zero | is usually not tuned, but is a reasonable value |
Learning Rate decay
It can sometimes make sense to keep the learning rate large at the beginning and then gradually reduce it the more the algorithm converges towards the optimum. This process is called learning rate decay (LRD). The reason LRD can make sense is that during the initial steps of optimization the algorithm can take larger steps whereas at the end it should take only small steps in order to oscillate within a smaller region around the optimum.
To implement LRD the learning rate starts out with an initial value and is then reduced after each epoch by calculating:
There are variations on this, for example:
- (exponential decay)
- or ( is a constant hyperparameter, is the number of the mini-batch)
- stepwise reduction after a few steps (discrete decay)
- manual decay: might work when only training a small number of models
Hyperparameter tuning
Until now we have seen quite a lot of hyperparmeters (learning rate , number of layers, number of hidden units, learning rate decay, …). Trying out all possible combinations of these would be infeasible. It also would not make much sense to try out all different combinations, because some of the parameters are more important than others thus a lot of meaningless combinations would also be tried. In practice you usually start out with random values and see where there are regions of values that produce good results. Some of the hyperparameters like the number of layers or hidden units could actually be systematically tried out using grid search, if they are normally distributed. For other parameters like the learning rate it makes most sense only to search in the interval . This is epsecially important for parameters like that are more sensitive (i.e. small changes on them can have a high impact on the performance of an algorithm). Such parameters should periodically be re-evaluated to see if the original intuition is still justified.
When tuning hyperparameters, there are generally two paradigms:
- Pandas: Only train one model on which you continuously fine-tune its hyperparameters. This is often done if computational power is scarce.
- Caviar: Train several models simultaneously and evaluate them. This is usually done if there is a lot of computational power available
These terms are derived from zoology because pandas usually have only one cub whereas sturgeons produce a lot of eggs (caviar).
Batch Normalization
We have seen that normalizing the input can lead to faster learning in the individual units. We can do this for any hidden layer by performing the following steps:
- Compute the mean of layer :
- Compute the variance of layer :
- Compute the layer norm:
- Compute the batch norm:
There is some debate whether to normalize the cell values before () or after activation (). In practice, the former is more common. The parameters and are learnable and can be different for each layer. They allow the mean and variance of to any value. For example, choosing and would lead to the same value as before normalization (identity function):
Using BN can lead to a much more robust NN, a broader range of possible hyperparameters and easier training of deep NN. BN is implemented in most common DL-Frameworks like TensorFlow or Keras. Most of the time you don’t have to fiddle with and . However, if you want to adjust the mean and/or variaince of your batch norm explicitly (i.e. to make use of some specific region of your activation function), there are parameters to do exactly that.
Why does BN work?
BN can improve the learning process dramatically. The reason for this is BN reduces the degree, to which input values for a given hidden layers vary (known as covariant shift, because mean and variance always lie within a certain region.
(to be extended)
Multiclass classification
Up to know we have only talked about binary classifiers. The output layer in these NN consisted of a single neuron whose Sigmoid activation function output the probability of an instance belonging to the target class (or not). However, we often have more than one target class, i.e. NN with more than one neuron.
In such networks we distinguish classes, i.e. , whereas each node indicates the probability of an instance belonging to a specific class. We can then use an activation function which is known as softmax which calculates the activation of this output layer as follows:
- calculate vector by element-wise exponentiation
- calculatae the activation by dividing by the sum of its elements:
In contrast to the other activations (Sigmoid, Tanh, …) softmax is a function from vector to vector. The sum of all elements in the activation value is 1. The term softmax indicates the classifier’s ability to express membership of an instance with a class not just binary but by probability. In that respect, sigmoid is kind of a special form of softmax for only two classes.
TLDR
Regularization
- Regularization will help you reduce overfitting.
- L2 regularization and Dropout are two very effective regularization techniques.
- L2-regularization in cost computation: A regularization term is added to the cost
- L2-regularization in backprop: There are extra terms in the gradients with respect to weight matrices
- weight decay: Weights are pushed to smaller values
- Dropout (randomly eliminate nodes): only use dropout during training. Don't use dropout during test time. Apply dropout both during forward and backward propagation
Initialization
- Different initializations lead to different results
- Random initialization is used to break symmetry and make sure different hidden units can learn different things
- Don't intialize to values that are too large
- He initialization works well for networks with ReLU activations.
Optimization
- The difference between gradient descent, mini-batch gradient descent and stochastic gradient descent is the number of examples you use to perform one update step.
- You have to tune a learning rate hyperparameter α
- With a well-turned mini-batch size, usually it outperforms either gradient descent or stochastic gradient descent (particularly when the training set is large).
- Shuffling and Partitioning are the two steps required to build mini-batches
- Momentum takes past gradients into account to smooth out the steps of gradient descent. It can be applied with batch gradient descent, mini-batch gradient descent or stochastic gradient descent.
- You have to tune a momentum hyperparameter ββ and a learning rate αα .